Last week, I reported here that researchers at Stanford University planned to augment a study they released of generative AI legal research tools from LexisNexis and Thomson Reuters, in which it found that they deliver hallucinated results more often than the companies say in their marketing of the products.
The study came under criticism for its omission of Thomson Reuters’ generative AI legal research product, AI-Assisted Research in Westlaw Precision. Rather, it reviewed Ask Practical Law AI, a research tool that is limited to content from Practical Law, a collection of how-to guides, templates, checklists, and practical articles.
The authors explained that Thomson Reuters had denied their multiple requests for access to the AI-Assisted Research product.
Shortly after the report came out, Thomson Reuters agreed to give the authors access to the product, and the authors said they would augment their results.
That augmented version of the study has now been released, and the Westlaw product did not fare well.
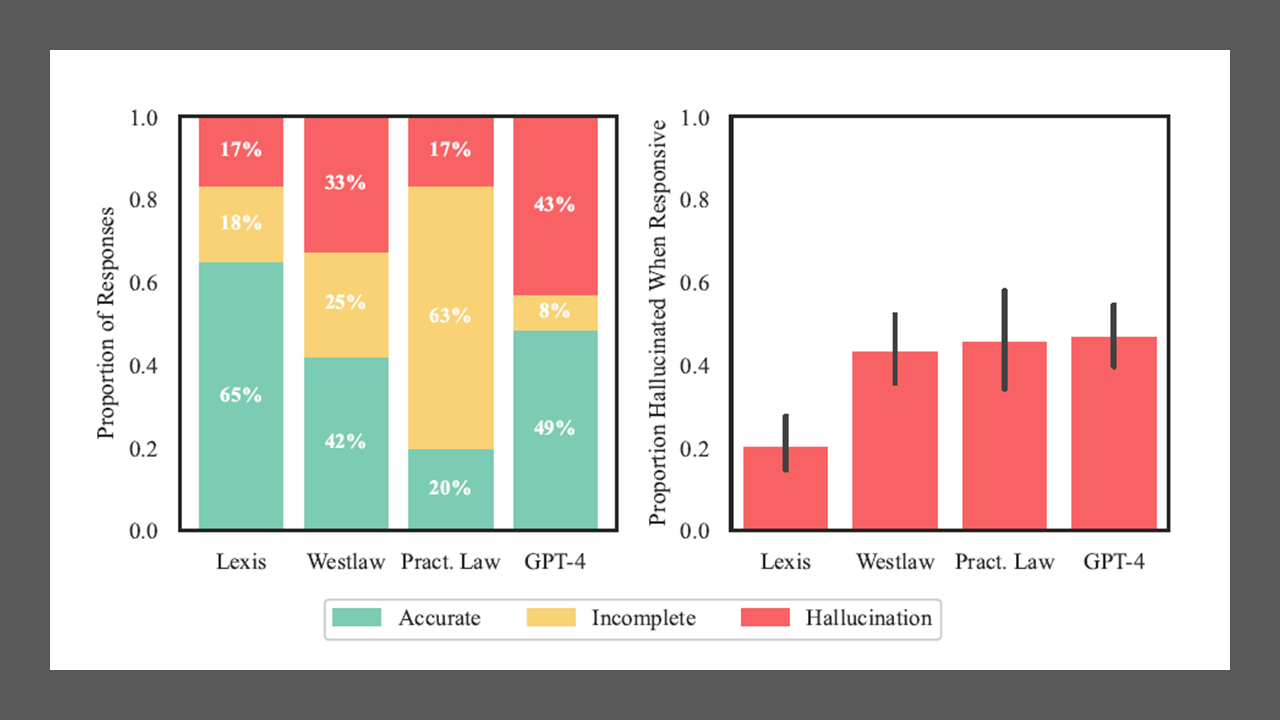
While the study found that the LexisNexis generative AI product, Lexis+ AI, correctly answered 65% of their queries, Westlaw’s AI-Assisted Research was accurate only 42% of the time.
Worse, Westlaw was found to hallucinate at nearly twice the rate of the LexisNexis product — 33% for Westlaw compared to 17% for Lexis+ AI.
“On the positive side, these systems are less prone to hallucination than GPT-4, but users of these products must remain cautious about relying on their outputs,” the study says.
One Reason: Longer Answers
One reason Westlaw hallucinates at a higher rate than Lexis is that it generates the longest answers of any of the products they tested, the authors speculate. Its answers average a length of 350 words, compared to 219 for Lexis and 175 for Practical Law.
“With longer answers, Westlaw contains more falsifiable propositions and therefore has a greater chance of containing at least one hallucination,” the study says. “Lengthier answers also require substantially more time to check, verify, and validate, as every proposition and citation has to be independently evaluated.”
That said, the study found that both Westlaw and Lexis “often offer high-quality responses.” It cited the examples of Lexis picking up a false premise in a question and clarifying the actual law and of Westlaw correctly understanding a nuanced question of patent law.
Still, the study expresses concern about the shortcomings in these systems and what that means for legal professionals:
“These systems can be quite helpful when they work. But as we now illustrate in detail, their answers are often significantly flawed. We find that these systems continue to struggle with elementary legal comprehension: describing the holding of a case … , distinguishing between legal actors (e.g., between the arguments of a litigant and the holding of the court), and respecting the hierarchy of legal authority. Identifying these misunderstandings often requires close analysis of cited sources. These vulnerabilities remain problematic for AI adoption in a profession that requires precision, clarity, and fidelity.”
In this revised report, as they did in the original version, the authors stress that they believe the most important takeaway from the study “is the need for rigorous, transparent benchmarking and public evaluations of AI tools in law.”
“In contrast to even GPT-4 — not to mention open-source systems like Llama and Mistral — legal AI tools provide no systematic access, publish few details about models, and report no benchmarking results at all,” the study says.