The AI legal research startup Descrybe today launched a “legal reasoning” product, DescrybeLM, that it says outperforms leading general-purpose AI models on a standardized legal reasoning benchmark — and it is publishing the methodology and scoring data to invite scrutiny.
The company also launched an all-new website that features the new product while also retaining all the functionality of its prior “Legal Research Toolkit,” which includes tools for conducting legal research by concept, keyword, case name, citation, and legal issue.
As the company says, DescrybeLM and the Legal Research Toolkit are “built to work together,” with the latter used to find the relevant law that bears on a question and the former then enabling users to reason through it against the specific facts of the matter at hand.
Benchmarking Against General AI
The company tested its new system against ChatGPT 5.2, Claude Opus 4.5 and Gemini 3 Pro on 200 questions from the National Conference of Bar Examiners MBE Complete Practice Exam. DescrybeLM answered all 200 correctly. The general-purpose models each missed between 13 and 23 questions, achieving accuracy rates ranging from 88.5% to 93.5%.
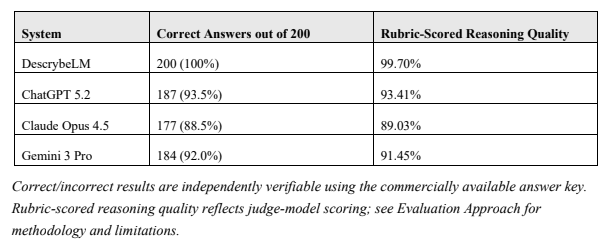
Rubric-scored reasoning quality — a separate measure evaluating whether systems correctly identified governing legal rules and applied them to the facts — followed a similar pattern. DescrybeLM scored 99.70% on that dimension. ChatGPT 5.2 scored 93.41%, Gemini 3 Pro scored 91.45%, and Claude Opus 4.5 scored 89.03%.
A central fcous of the study was not just whether AI systems get legal questions wrong, but rather how they get them wrong. Among the 52 incorrect outputs produced by the three general-purpose models, 49 were flagged as “confidently wrong” — assertive, fluent, well-structured responses that gave no signal of uncertainty. The dominant failure patterns were applying the wrong legal standard to the facts, or applying the correct standard incorrectly.
“When these systems were wrong, they were confidently wrong,” the benchmarking study said. “Among the 52 total incorrect outputs, the dominant failure patterns applied the wrong legal standard or misapplied the correct one, while presenting the analysis in fluent, well-structured prose. These are precisely the errors that impose the highest verification burden on practitioners.”
The study also found that cross-checking between general-purpose models is an unreliable safeguard. Across the 200 questions, 40 were missed by at least one of the three models, but only one question was missed by all three. Because errors were largely non-overlapping and unpredictable, model disagreement does n0t reliably identify which output is correct, it only signals that verification is needed.
The scoring log found that two general-purpose models — Claude Opus 4.5 and Gemini 3 Pro — were flagged for overconfidence on correct outputs as well as incorrect ones. Claude Opus 4.5 received three overconfidence flags total, one on a wrong answer and two on correct ones. Gemini 3 Pro received one overconfidence flag on a correct answer. ChatGPT 5.2 and DescrybeLM received zero overconfidence flags across all 200 outputs.
The study interprets this as a model-level stylistic tendency, not simply a byproduct of being wrong. A system that applies the same assertive tone regardless of whether its answer is correct, the white paper argues, gives legal practitioners less reliable signal from output confidence alone.
“We had a thesis that purpose-built legal AI produces meaningfully different results for legal reasoning tasks,” said Kara Peterson, Descrybe’s cofounder and CEO. “Legal professionals deserve to make tool decisions based on real evidence, which can be hard to find. So, we tested ourselves.”
Peterson said she understands that vendor-produced benchmarks invite scrutiny. “That’s why we published our methodology and invite anyone to replicate it,” she said.
What’s Behind DescrybeLM
Descrybe describes the focus of this study, its new DescrybeLM, as a legal reasoning engine and drafting workspace. It enables users to receive authority-grounded analysis to complex legal questions and then to refine that analysis through clarifying follow-ups.
(Descrybe invited me to test the new product in advance of today’s launch. Because of my own tight schedule, I was unable to do so, but I still plan to at a later point and will report back when I do.)
It is built, the company says, on a curated primary law corpus of more than 100 million structured records, processed at a scale requiring more than 100 billion tokens of preparation. The system is designed to produce verification-friendly outputs that include clear rule statements, application to key facts, and structured reasoning.
You can see it demonstrated in this video:
“Most AI tools are built for general use and adapted for law,” said Richard DiBona, cofounder and CTO. “DescrybeLM was built differently: from the foundation up, specifically for legal reasoning, on more than 100 million structured records individually cleaned and organized for that purpose.”
In the study, the company chose to benchmark only against general-purpose models rather than other AI platforms specifically built for legal research. I asked Peterson why that was.
She explained that the company’s central question was what distinguishes foundation models from purpose-built tools, and that the best way to test that thesis was to put themselves directly in comparison against those models. Peterson emphasized that she strongly encourages other legal AI vendors to run the same benchmark using the same methodology.
Caveats the Company Itself Raises
Descrybe is transparent about the possible limitations of its own study, which it spells out in the report.
Most notably, the company says that it cannot rule out that some or all of the 200 questions appeared in the training data of the evaluated systems, including its own DescrybeLM. The MBE Complete Practice Exam is a commercially available product. That caveat applies equally to all systems tested, but a perfect score on a published question set will invite more scrutiny than a score of, say, 93%.
The study also discloses that fine-tuning performed on DescrybeLM before the benchmark was conducted on a separate NCBE product, not the question set used in the evaluation, and that the NCBE answer key was not provided to the system during testing.
Among other limitations: the benchmark covers only multiple-choice legal reasoning and does not test drafting, jurisdiction-specific research, citation accuracy or other real-world legal workflows. The evaluation was conducted entirely by the team that built DescrybeLM. Scoring was executed by an AI judge model — specifically, GPT-5.2 extra high reasoning, which is in the same model family as one of the evaluated systems. And each question was run only once per system, meaning the results do not come with confidence intervals or variance data.
On the rubric design, the company acknowledges the possibility of unconscious bias favoring DescrybeLM’s output style, but says it mitigated that risk through three measures: the rubric was authored by a human subject-matter expert and pre-committed before scoring began; all outputs were anonymized before the judge model applied the rubric; and the same rubric, judge prompt, and settings were applied identically across all 800 outputs.
DescrybeLM’s perfect accuracy score did not imply perfect reasoning. Twenty-seven of its outputs received rubric scores below 100, mostly for incomplete distractor discussion or alternative doctrinal framing — that is, reaching the correct answer via a different but defensible legal standard than the one emphasized by the reference answer. No DescrybeLM output was flagged for wrong rule, misapplied rule, misread key fact, or internal contradiction.
Inviting Replication
As noted, the company has published its full methodology, scoring rubric, standardized prompt and a per-output scoring log covering all 800 model outputs across the four systems. The NCBE question set is commercially available, and Descrybe says any researcher or vendor can purchase it and independently replicate the benchmark.
Because of model non-determinism and ongoing provider updates, exact numerical replication is unlikely, the company says, but directional replication, including rank ordering and approximate accuracy ranges, is the expected standard.
“I’ve worked in legal technology for a long time,” said Ken Friedman, founder of the legal tech practice group at law firm L&F Brown and a strategic advisor to the company. “It’s rare to see something that genuinely stops you in your tracks. When I saw DescrybeLM answer all 200 multistate bar exam questions correctly while ChatGPT, Claude and Gemini each missed double digits, that’s exactly what happened.”
Here is the full white paper: Beyond Confidently Wrong: How Purpose-Built AI Mitigates Legal Reasoning’s Hidden Risk.